Explication du rc.firewall
Options de configuration
La premičre section de l'exemple rc.firewall.txt est la section de configuration. Elle devra toujours ętre modifiée car elle contient des informations vitales pour votre configuration. Par exemple, votre adresse IP changera. Le $INET_IP devra toujours ętre une adresse IP totalement valide, si vous en avez une (sinon regardez de plus prčs le rc.DHCP.firewall.txt). Également, la variable $INET_IFACE devra pointer vers le matériel utilisé pour votre connexion Internet. Ce peut ętre eth0, eth1, ppp0, tr0, etc., pour citer quelques noms d'interfaces.
Ce script ne contient aucune option de configuration spéciale pour DHCP ou PPPoE, c'est pourquoi ces sections sont vides. Męme chose pour toutes les sections vides, elles sont cependant indiquées, ainsi vous pouvez voir la différence entre les scripts de façon plus efficace. Si vous avez besoin de ces parties, vous pouvez toujours créer un mélange des différents scripts, ou créer le votre entičrement.
La section concernant votre réseau local contient la plupart des options de configuration nécessaires. Par exemple, vous avez besoin de spécifier l'adresse IP d'une interface physique connectée au LAN de męme que la plage IP que le LAN utilise et l'interface par laquelle la machine est connectée au réseau.
Ainsi, vous pouvez voir qu'il y a une section pour la configuration de l'hôte local. Nous vous la fournissons, cependant vous n'effecturez ŕ 99% aucun changement dans ces valeurs car on utilise presque toujours l'adresse IP 127.0.0.1 et l'interface nommée lo. Juste aprčs la configuration de l'hôte local, vous trouverez une brčve section qui appartient ŕ iptables. Cette section concerne les variables $IPTABLES, qui pointent le script vers l'endroit exact oů se trouve l'application iptables. Ceci peut varier un peu, et l'endroit par défaut lors de la compilation ŕ la main est /usr/local/sbin/iptables. Cependant, plusieurs distributions placent l'application ŕ un autre endroit comme /usr/sbin/iptables ou /sbin/iptables.
Chargement initial des modules supplémentaires
Premičrement, regardons si les fichiers des dépendances des modules sont ŕ jour en exécutant la commande /sbin/depmod -a. Aprčs ça chargeons les modules nécessaires au script. Évitez toujours de charger des modules dont vous n'avez pas besoin. C'est pour des raisons de sécurité, car il sera plus difficile d'établir des rčgles supplémentaires de cette façon. Maintenant, par exemple, si vous voulez avoir le support des cibles LOG, REJECT et MASQUERADE et ne les avez pas compilées statiquement dans le noyau, vous devrez charger ces modules comme suit :
/sbin/insmod ipt_LOG
/sbin/insmod ipt_REJECT
/sbin/insmod ipt_MASQUERADE
|
 | Dans ces scripts, nous chargeons les modules de force, ce qui peut conduire ŕ des problčmes. Si un module ne se charge pas, ce qui peut dépendre de plusieurs facteurs, il enverra un message d'erreur. Si certains modules les plus basiques ne se chargent pas, l'erreur la plus probable est que le module, ou la fonctionnalité, est compilée statiquement dans le noyau. Pour plus d'information sur ce sujet, lisez la section Problčmes de chargement des modules dans l'annexe Problčmes et questions courants. |
Ensuite c'est le module ipt_owner ŕ charger, qui peut, par exemple, ętre utilisé pour permettre ŕ certains utilisateurs de réaliser certaines connexions, etc. Je n'utilise pas ce module dans l'exemple, mais vous pouvez autoriser seulement root ŕ se connecter en FTP et HTTP ŕ redhat.com et DROP tous les autres. Vous pouvez aussi interdire tous les utilisateurs sauf vous et root de se connecter depuis votre machine ŕ l'Internet. Ça peut ętre ennuyeux pour les autres, mais vous aurez plus de sécurité par rapport aux attaques oů le hacker utilise seulement votre machine comme hôte intermédiaire. Pour plus d'information sur ipt_owner regardez la section Correspondance owner dans le chapitre Création d'une rčgle.
Vous pouvez aussi charger des modules supplémentaires pour le code de correspondance d'état ici. Tous les modules additionnels au code de correspondance d'état et au code de traçage de connexion sont appelés ip_conntrack_* et ip_nat_*. Les assistants de traçage de connexion sont des modules spéciaux qui indiquent au noyau comment tracer correctement les connexions spécifiques. Sans ces assistants, le noyau ne sait pas quoi chercher quand il essaie de tracer des connexions. Les assistants NAT d'un autre côté, sont des extensions des assistants de traçage de connexion qui indiquent au noyau que rechercher dans des paquets spécifiques et comment traduire ceux-ci dans les connexions en cours. Par exemple, FTP est un protocole complexe par définition, il envoit des informations de connexion dans les données utiles du paquet. Donc, si une de vos machines NATées se connecte ŕ un serveur FTP sur l'Internet, elle enverra sa propre adresse IP du réseau local dans les données utiles du paquet, et indiquera au serveur FTP de se connecter ŕ cette adresse. Étant donné que adresse du réseau locale n'est pas valide en dehors de votre propre réseau, le serveur FTP ne saura pas que faire avec elle et la connexion sera coupée. Les assistants FTP NAT font les traductions qui permettent au serveur FTP de savoir oů se connecter. La męme chose s'applique pour les transferts de fichiers en DCC dans les chats irc. Créer ce genre de connexions nécessite une adresse IP et des ports ŕ envoyer au protocole IRC, lequel en retour demande que certaines traductions soient faites. Sans ces assistants, FTP et IRC fonctionneront sans doute, cependant, certaines autres choses ne marcheront pas. Par exemple, vous pouvez recevoir des fichiers par DCC, mais pas en envoyer. Ceci est dű ŕ la façon dont DCC démarre une connexion. En premier, vous indiquez au destinataire que vous voulez envoyer un fichier et oů il devra se connecter. Sans les assistants, la connexion DCC ressemblera ŕ une tentative du receveur de connecter certains hôtes au propre réseau local de ce receveur. La connexion sera brisée. Cependant, ça peut fonctionner sans défaut, car l'expéditeur vous enverra (probablement) la bonne adresse pour vous connecter.
 | Si vous rencontrez des problčmes avec le DCC de mIRC et que tout fonctionne correctement avec d'autres clients IRC, lisez la section Problčmes avec le DCC de mIRC dans l'appendice Problčmes et questions courants. |
Comme nous l'avons écrit, c'est seulement l'option de chargement des modules qui ajoute le support pour les protocoles FTP et IRC. Pour une explication plus détaillée des modules conntrack et nat, lisez l'annexe Problčmes et questions courants. Il existe aussi les assistants conntrack H.323 dans le patch-o-matic, comme d'autres assistants conntrack et NAT. Pour pouvoir vous en servir, vous devez utiliser le patch-o-matic et compiler votre propre noyau. Pour une explication plus complčte, voir le chapitre Préparatifs.
| Notez que vous devrez charger ip_nat_irc et ip_nat_ftp si vous voulez que la traduction d'adresse réseau fonctionne correctement avec les protocoles FTP et IRC. Vous aurez également besoin de charger les modules ip_conntrack_irc et ip_conntrack_ftp avant de charger les modules NAT. Ils sont utilisés de la męme façon que les modules conntrack, mais ils vous permettront de faire du NAT sur ces deux protocoles. |
Réglage du proc
Ici nous démarrons le IP forwarding par un écho ŕ 1 sur /proc/sys/net/ipv4/ip_forward de cette façon :
echo "1" > /proc/sys/net/ipv4/ip_forward
 | Il peut ętre intéressant de réfléchir oů et quand nous devons placer l'IP forwarding (transfert IP). Dans ce script, et dans tous les autres de ce didacticiel, nous le plaçons avant de créer les autres filtres IP (i.e., les rčgles de iptables). Ceci conduit ŕ une brčve période de temps pendant laquelle le pare-feu accepte le transfert de tout le trafic, entre une milliseconde et une minute selon le script. Ceci peut permettre ŕ des personnes malicieuses d'essayer de passer le pare-feu. En d'autres termes, cette option doit ętre activée aprčs la création de toutes les rčgles, cependant, j'ai choisi de l'activer avant de charger d'autres rčgles pour des raisons de concordance avec le script. |
Dans le cas oů vous avez besoin du support d'adresse IP dynamique, par exemple vous utilisez SLIP, PPP ou DHCP, vous devez acitver l'option ip_dynaddr en faisant :
echo "1" > /proc/sys/net/ipv4/ip_dynaddr
S'il y a d'autres options que vous voulez activer vous suivez cette procédure. Il existe d'autres documentations sur ces sujets mais c'est hors du sujet de ce didacticiel. Il existe un bon mais bref document sur le systčme proc disponible dans le noyau, également disponible dans l'annexe Autres ressources et liens. L'annexe Autres ressources et liens est généralement un bon endroit pour rechercher l'information que vous ne trouvez pas ici.
| Le script rc.firewall.txt, et tous les autres scripts de ce didacticiel, contient une petite section sur la mise en place des proc qui ne sont pas requises. Ce peut ętre lŕ qu'il faut regarder quand quelque chose ne fonctionne pas comme vous le voulez, cependant, ne changez pas les valeurs avant de savoir ce qu'elles représentent. |
Déplacement des rčgles vers différentes chaînes
Cette section décrit bričvement mes choix en fonction des scripts spécifiques du rc.firewall.txt. Certains des chemins d'accčs indiqués ici peuvent ętre faux selon un ou un autre aspect. Aussi, cette section jette en bref regard en arričre sur le chapitre Traversée des tables et des chaînes. Nous nous souviendrons de la façon dont les tables et les chaînes sont traversées dans un exemple réel.
J'ai modifié toutes les différentes chaînes utilisateur de façon ŕ économiser le plus possible de CPU, mais en męme temps en mettant l'accent principal sur la sécurité et la fiabilité. Au lieu de laisser un paquet TCP traverser les rčgles ICMP, UDP et TCP, j'ai simplement apparié tous les paquets TCP et laissé ces paquets TCP traverser les chaînes spécifiées par l'utilisateur. De cette façon nous ne consommons pas trop de temps systčme. L'image ci-dessous tente d'expliquer comment un paquet entrant traverse Netfilter. Avec ces images et explications, j'essaie de clarifier les buts de ce script. Nous ne verrons cependant aucun détail spécifique, ceci sera fait plus loin dans le chapitre. C'est un image plutôt triviale en comparaison de celle du chapitre Traversée des tables et des chaînes oů nous parlons de la traversée complčte des tables et des chaînes en profondeur.
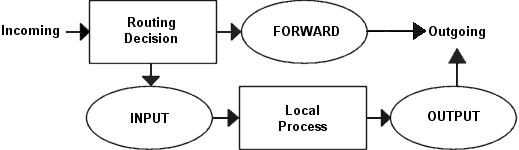
Nous fondant sur cette image, clarifions nos buts. C'est un exemple complet de script basé sur la supposition que notre scenario contient un réseau local, un pare-feu et une connexion Internet connectée ŕ ce pare-feu. Cet exemple est aussi basé sur la supposition que nous avons une adresse IP statique vers l'Internet (ŕ l'opposé de DHCP, PPP, SLIP et autres). Dans ce cas, nous voulons autoriser le pare-feu ŕ agir comme serveur pour certains services sur l'Internet, et nous faisons pleinement confiance ŕ notre réseau local et donc ne bloquons pas le trafic provenant de celui-ci. Pour faire ceci, nous plaçons les stratégies des chaînes par défaut ŕ DROP. Ce qui effectivement bloquera toutes les connexions et tous les paquets que nous n'avons pas explicitement autorisés dans notre réseau ou notre pare-feu.
Dans le cas de ce scenario, nous laisserons notre réseau local se connecter ŕ l'Internet. Comme nous avons pleine confiance dans notre réseau, nous permettons toute sorte de trafic depuis ce réseau local vers l'Internet. Cependant, l'Internet n'est pas un réseau de confiance et donc nous voulons bloquer les connexions venant de celui-ci et allant vers notre réseau. En fonction de ces suppositions, regardons ce que nous devons faire et ne pas faire.
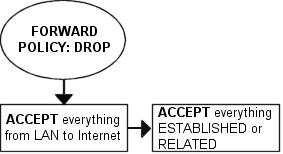
En priorité, nous voulons que notre réseau local puisse se connecter ŕ l'Internet, bien sűr. Pour cela, nous devons NATer tous les paquets car aucune de nos machines locales n'a d'adresse IP routable. Tout ceci est effectué dans la chaîne POSTROUTING, créée en dernier dans le script. Nous devons aussi faire du filtrage dans la chaîne FORWARD car nous devons permettre un accčs complet ŕ notre réseau local. Nous avons confiance dans notre réseau local, et pour ça nous autorisons tout le trafic provenant de celui-ci et allant vers l'Internet. Comme personne sur l'Internet ne sera autorisé ŕ se connecter aux ordinateurs de notre réseau local, nous bloquerons tout le trafic provenant de l'Internet vers le réseau local sauf les connexions déjŕ établies, qui autorisent le trafic en réponse.

Comme pour notre pare-feu, nous n'avons peut-ętre pas trop de moyens, et ne voulons offrir que quelques services sur l'Internet. Nous avons décidé de permettre les accčs HTTP, FTP, SSH et IDENTD ŕ notre pare-feu. Tous ces protocoles sont disponibles dans le pare-feu, et seront donc autorisés par la chaîne INPUT, ainsi que nous autoriserons le trafic en retour ŕ travers la chaîne OUTPUT. Cependant, nous avons pleinement confiance dans notre réseau local, et le matériel local et l'adresse IP sont également sűrs. Donc, nous pouvons ajouter des rčgles spéciales pour permettre le trafic depuis le réseau local comme depuis la boucle locale. De męme, nous n'autoriserons pas certains paquets spécifiques, ni certaines plages d'adresses IP ŕ joindre le pare-feu depuis l'Internet. Par exemple, la plage d'adresses IP 10.0.0.0/8 est réservée ŕ notre réseau local et donc nous ne voulons pas autoriser les paquets provenant d'une de ces adresses car ils risqueraient ŕ 99% une usurpation d'adresse. Cependant, avant d'implémenter ceci, nous devons noter que certains fournisseurs d'accčs Internet (FAI) utilisent ces plages d'adresses IP dans leur propre réseau. Pour plus de détails, voir le chapitre Problčmes et questions courants.
Comme nous avons un serveur FTP actif, et que nous voulons traverser certaines rčgles, nous ajoutons une rčgle qui permet le trafic établi et relié au début de la chaîne INPUT. Pour la męme raison, nous divisons les rčgles en sous-chaînes. En faisant ça, nos paquets n'auront besoin de traverser que quelques chaînes. En traversant moins de chaînes, nous consommons moins de temps pour chaque paquet, et réduisons la latence dans le réseau.
Dans ce script, nous choisissons de diviser les différents paquets par leur famille de protocole, par exemple TCP, UDP ou ICMP. Tous les paquets TCP traversent une chaîne spécifique nommée tcp_packets, qui contient les rčgles pour tous les ports et protocoles TCP que nous voulons autoriser. Ainsi, si nous voulons faire certaines vérifications supplémentaires sur les paquets TCP, nous devrons créer une sous-chaîne pour tous les paquets acceptés qui utilisent des numéros de port valides vers le pare-feu. Cette chaîne que nous choisissons d'appeler chaîne autorisée, contiendra certaines vérifications supplémentaires avant d'accepter le paquet. Pour les paquets ICMP, ils traversent la chaîne icmp_packets. Quand nous avons décidé de créer cette chaîne, nous n'avons pas vu le besoin de vérifications supplémentaires avant d'accepter les paquets s'ils sont conformes au code ICMP, et donc les acceptons directement. Enfin, nous avons les paquets UDP qui doivent ętre distribués avec. Nous envoyons ces paquets vers la chaîne udp_packets qui traite tous les paquets UDP entrants. Tous les paquets UDP entrants doivent ętre envoyés ŕ cette chaîne, et s'ils sont d'un type autorisé nous les acceptons immédiatement sans vérification supplémentaire.
Comme nous sommes sur un réseau relativement petit, cette machine étant également utilisée comme station de travail secondaire, nous voulons autoriser certains protocoles spécifiques ŕ joindre le pare-feu, comme speak freely et ICQ.
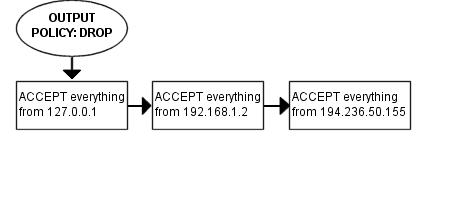
Enfin, nous avons la chaîne OUTPUT. Comme nous faisons confiance ŕ notre pare-feu, nous autorisons tout le trafic quittant celui-ci. Nous ne bloquons aucun utilisateur, ni aucun protocole spécifique. Cependant, nous ne voulons pas que des personnes utilisent cette machine pour usurper les paquets quittant le pare-feu, et donc autorisons uniquement le trafic depuis les adresses assignées au pare-feu. Nous implémenterons ceci en ajoutant des rčgles qui ACCEPT tous les paquets quittant le pare-feu lorsque ceux-ci proviennent des adresses assignées, s'ils ne sont pas supprimés par défaut dans la chaîne OUTPUT.
Mise en place des actions par défaut
Trčs tôt dans le processus de création de nos rčgles, nous avons placé nos stratégies par défaut. Nous implémentons nos stratégies par défaut dans les différentes chaînes avec une commande trčs simple, comme décrite ci-dessous :
iptables [-P {chain} {policy}]
La stratégie par défaut est utilisée chaque fois que les paquets n'apparient pas une rčgle dans une chaîne. Par exemple, nous avons un paquet qui n'apparie aucune rčgle dans notre table de rčgles. Si ça se produit, nous devons décider quoi faire du paquet en question, et c'est lŕ qu'intervient la stratégie par défaut. Elle est utilisée sur tous les paquets qui ne s'apparient avec aucune rčgle dans notre table de rčgles.
| Faîtes attention avec la stratégie par défaut que vous placez sur des chaînes dans d'autres tables, car elle n'est pas conçue pour le filtrage, et peut provoquer des comportements étranges. |
Implémentation des chaînes utilisateur dans la table filtre
Maintenant que nous avons une bonne image de ce que nous voulons faire avec ce pare-feu, voyons l'implémentation de la table de rčgles. C'est le moment de faire attention ŕ l'implémentation des rčgles et des chaînes que nous voulons créer, de męme que les tables de rčgles dans les chaînes.
Aprčs cela, nous créons les différentes chaînes spéciales que nous voulons utiliser avec la commande -N. Les nouvelles chaînes sont créées et implémentées sans aucune rčgle ŕ l'intérieur. Les chaînes que nous utilisons sont, comme précédemment décrit, icmp_packets, tcp_packets, udp_packets et les chaînes autorisées, qui sont utilisées par la chaîne tcp_packets. Les paquets entrants sur $INET_IFACE, de type ICMP, seront redirigés vers la chaîne icmp_packets. Les paquets de type TCP, seront redirigés vers la chaîne tcp_packets et les paquets entrants de type UDP venant de $INET_IFACE iront vers la chaîne udp_packets. Tout ceci sera expliqué en détail dans la section Chaîne INPUT ci-dessous. Créer une chaîne est tout ŕ fait simple et consiste seulement en une déclaration de chaîne comme ceci :
iptables [-N chain]
Dans les sections suivantes nous verrons les chaînes définies par l'utilisateur que nous avons créées. Regardons ŕ quoi elles ressemblent, quelles rčgles elles contiennent et ce que nous pouvons faire avec.
La chaîne bad_tcp_packets
La chaîne bad_tcp_packets est destinée ŕ contenir les rčgles qui vérifient les paquets entrants avec des en-tętes mal formés ou d'autres problčmes. Nous avons choisi d'inclure seulement un filtre de paquet qui bloque tous les paquets TCP entrants qui sont considérés comme NEW mais n'ont pas le bit SYN placé, et une rčgle qui bloque les paquets SYN/ACK considérés comme NEW. Cette chaîne peut ętre utilisée pour vérifier toutes les contradictions possibles, comme ci-dessus ou les balayages de port XMAS, etc. Nous pourrions de męme ajouter des rčgles pour l'état INVALID.
Si vous voulez pleinement comprendre le NEW non SYN, regardez la section Paquets état NEW sans bit SYN placé dans l'annexe Problčmes et questions courants en relation avec NEW et les paquets non-SYN. Ces paquets seront autorisés dans certaines circonstances mais dans 99% des cas nous n'en aurons pas besoin. Nous pouvons les journaliser et ensuite les supprimer.
La raison pour laquelle nous rejetons les paquets SYN/ACK qui sont considérés comme NEW est trčs simple. C'est décrit en détail dans la section SYN/ACK et les paquets NEW de l'annexe Problčmes et questions courants.
La chaîne autorisée
Si un paquet de type TCP arrive sur l'interface $INET_IFACE, il traverse la chaîne tcp_packets et si la connexion est sur un port sur lequel nous voulons autoriser le trafic, nous ferons certaines vérifications finales sur ce port pour savoir s'il est actuellement autorisé ou non. Toutes ces vérifications finales sont faites dans la chaîne autorisée.
En premier, nous vérifions si le paquet est un paquet SYN. Si c'est le cas, il y a de fortes chances pour que ce soit le premier paquet d'une nouvelle connexion, nous l'autorisons. Ensuite nous vérifions si le paquet provient d'une connexion ESTABLISHED ou RELATED, et si c'est encore le cas nous l'autorisons. Une connexion ESTABLISHED est une connexion qui a observé le trafic dans les deux sens, et donc nous avons un paquet SYN, cette connexion doit ętre dans l'état ESTABLISHED, selon la machine d'état. La derničre rčgle dans cette chaîne DROP tout le reste. Dans ce cas ceci indique que tout le trafic n'a pas été forcément observé dans les deux directions, i.e., nous n'avons pas répondu au paquet SYN, ou qu'il y a eu une tentative de connexion sans paquet SYN. Il n'y a pas, dans la pratique, de démarrage de connexion sans paquet SYN, sauf dans le cas oů des personnes font du balayage de port. Actuellement, il n'y a pas d'implémentation TCP/IP qui supporte l'ouverture d'une connexion TCP avec autre chose qu'un paquet SYN ŕ ma connaissance, donc nous faisons un DROP car nous sommes ŕ 99% sűrs qu'il s'agit alors d'un balayage de port.
La chaîne TCP
La chaîne tcp_packets spécifie quels ports provenant de l'Internet sont autorisés dans le pare-feu. Il y a cependant, quelques vérifications supplémentaires ŕ faire, ainsi nous envoyons chaque paquet vers la chaîne autorisée, comme décrit précédemment.
-A tcp_packets indique ŕ iptables dans quelle chaîne ajouter la nouvelle rčgle, celle-ci étant ajoutée ŕ la fin de la chaîne. -p TCP indique d'apparier les paquets TCP et -s 0/0 apparie toutes les adresses source provenant de 0.0.0.0 avec un masque de réseau de 0.0.0.0, en d'autres termes toutes les adresses source. C'est le comportement par défaut mais je l'utilise ici pour rendre les choses le plus clair possible. --dport 21 indique le port de destination 21, si le paquet est destiné au port 21 il est aussi vérifié. Si tous les critčres sont appariés, le paquet sera dirigé vers la chaîne autorisée. S'il n'apparie aucune des rčgles, elles seront renvoyées ŕ la chaîne qui a expédié le paquet vers la chaîne tcp_packets.
Comme cela maintenant, il autorise le port TCP 21, ou le port de contrôle FTP, qui sert ŕ contrôler les connexions FTP et plus tard les connexions RELATED, ainsi nous autorisons les connexions PASSIVE et ACTIVE car le module ip_conntrack_ftp est chargé. Si nous ne voulons pas du tout autoriser le FTP, nous pouvons décharger le module ip_conntrack_ftp et supprimer la ligne $IPTABLES -A tcp_packets -p TCP -s 0/0 --dport 21 -j allowed du fichier rc.firewall.txt.
Le port 22 est le port SSH, qu'il est beaucoup mieux d'utiliser que de permettre le telnet sur le port 23 si vous voulez autoriser quelqu'un de l'extérieur ŕ utiliser un shell sur votre machine. Notez que c'est toujours une mauvaise idée de permettre ŕ quelqu'un d'autre que vous męme d'avoir accčs ŕ une machine pare-feu.
Le port 80 est le port HTTP, en d'autres termes votre serveur web, supprimez le si vous ne voulez pas exécuter un serveur web directement sur votre pare-feu.
Enfin, nous autorisons le port 113, qui est le IDENTD et peut ętre nécessaire pour certains protocoles comme IRC, etc. Notez qu'il peut ętre intéressant d'utiliser le paquetage oidentd si vous faites du NAT sur plusieurs hôtes de votre réseau local. oidentd possčde un support pour faire du relaying des requętes IDENTD vers les bonnes machines de votre réseau local.
Si vous voulez ajouter d'autres ports dans ce script, c'est le moment. Simplement, copiez et coller une des autres lignes de la chaîne tcp_packets et modifiez la en fonction des ports que vous voulez ouvrir.
La chaîne UDP
Si nous obtenons un paquet UDP dans la chaîne INPUT, nous l'envoyons alors vers udp_packets oů il sera de nouveau apparié pour le protocole UDP avec -p UDP et ensuite vérifié avec l'adresse source 0.0.0.0 et le masque de réseau 0.0.0.0. Sauf que cette fois, nous n'acceptons que les ports UDP spécifiques que nous voulons ouvrir pour les hôtes de l'Internet. Notez que nous ne créons pas de trous sur le port source des hôtes expéditeurs, car il en sera pris soin par la machine d'état. Nous n'avons besoin d'ouvrir des ports sur notre hôte que si nous devons faire tourner un serveur sur un port UDP, comme le DNS, etc. Les paquets entrants dans le pare-feu et qui font partie d'une connexion déjŕ établie (par notre réseau local) seront automatiquement acceptés par les rčgles --state ESTABLISHED,RELATED au début de la chaîne INPUT.
Ainsi, nous ne plaçons pas le ACCEPT sur les paquets UDP entrants provenant du port 53, celui qui est utilisé pour le DNS. La rčgle existe mais elle est commentée par défaut. Si vous voulez que votre pare-feu agisse comme serveur DNS, décommentez la.
j'ai personnellement autorisé le port 123, port NTP ou network Time Protocol. Ce protocole est utilisé pour synchroniser l'horloge de votre machine avec des serveurs de temps qui sont trčs précis. La plupart d'entre vous n'utilise sans doute pas ce protocole et je ne l'ai donc pas autorisé par défaut. Il suffit aussi de décommenter la rčgle pour l'activer.
Nous n'autorisons pas le port 2074, utilisé par certains programmes multimedia comme speak freely qui servent ŕ parler avec d'autres personnes en temps réel en utilisant des haut-parleurs et des microphones, ou męme un casque d'écoute. Si vous voulez vous en servir décommentez simplement la ligne.
Le port 4000 est celui du protocole ICQ. C'est un protocole trčs bien connu qui est utilisé par le programme Mirabilis nommé ICQ. Il existe au moins 2 ou 3 clones de ICQ pour Linux et c'est un des programmes de chat les plus utilisés dans le monde. Je doute qu'il soit besoin d'en expliquer d'avantage.
Ŕ ce point, deux rčgles supplémentaires sont disponibles si vous avez fait l'expérience de certaines entrées de journaux dans certaines circonstances. La premičre rčgle bloque la diffusion des paquets vers les ports de destination 135 ŕ 139. Ils sont utilisés par NETBIOS, ou SMB pour les utilisateurs de Microsoft. Ceci bloque toutes les entrées de journaux provenant de iptables qui journalise l'activité de réseaux Microsoft ŕ l'extérieur de notre pare-feu. La seconde rčgle a été créée pour prévenir les problčmes de journalisation excessive, et prend soin des requętes DHCP provenant de l'extérieur. Ceci est particuličrement vrai si votre réseau extérieur est de type Ethernet non-commuté, dans lequel les clients obtiennent leur adresses IP par DHCP. Dans ces circonstances vous pouvez avoir beaucoup d'entrées de journal juste pour ça.
| Notez que ces deux derničres rčgles sont désactivées car certaines personnes peuvent ętre intéressées par ce genre de logs. Si vous rencontrez des problčmes avec une journalisation excessive, essayez de supprimer ce type de paquetages ŕ ce niveau. Il y a aussi beaucoup de rčgles de ce type juste avant les rčgles de log dans la chaîne INPUT. |
La chaîne ICMP
C'est lŕ que nous décidons quels types ICMP autoriser. Si un paquet de type ICMP arrive sur eth0 dans la chaîne INPUT, nous le redirigeons vers la chaîne icmp_packets comme expliqué plus haut. Ici nous consignons quels types ICMP autoriser. Pour le moment, j'autorise seulement les requętes écho ICMP entrantes, TTL égale 0 pendant le transit et TTL égale 0 pendant le réassemblage. La raison pour laquelle nous n'autorisons aucun autre type ICMP par défaut, est que la plupart des autres types ICMP seront pris en charge par les rčgles d'état RELATED.
| Si un paquet ICMP est envoyé en réponse ŕ un paquet déjŕ existant il est considéré comme RELATED par rapport au flux d'origine. Pour plus d'information sur les états, voir le chapitre La machine d'état. |
La raison pour laquelle j'autorise ces paquets ICMP est la suivante, les Requętes Écho servent aux réponses écho, utilisées principalement pour "pinguer" d'autres hôtes, pour voir s'ils sont disponibles sur les réseaux. Sans cette rčgle, d'autres hôtes ne pourraient pas nous "pinguer" pour vérifier que nous sommes présent dans une connexion réseau. Notez que certaines personnes ont tendance ŕ supprimer cette rčgle, car ils ne veulent pas ętre vus sur Internet. Supprimer cette rčgle rend effectivement inefficace tous les pings vers notre pare-feu depuis l'Internet car le pare-feu ne répondra tout simplement pas.
Time Exceeded (i.e., TTL égale 0 pendant le transit et TTL égale 0 pendant le réassemblage), est autorisé dans le cas oů nous voulons faire du traçage de route sur certains hôtes ou si un paquet a un TTL pacé ŕ 0, nous obtiendrons une réponse en retour. Par exemple, quand vous faites un traceroute sur quelqu'un, vous commencez avec un TTL = 1, et il obtient en retour un 0 au premier saut de son chemin, et un Time Exceeded est envoyé depuis la premičre passerelle de la route vers l'hôte que vous voulez tracer, ensuite le TTL = 2 et la seconde passerelle envoie un Time Exceeded, et ainsi de suite jusqu'ŕ ce que vous obteniez une réponse de l'hôte que vous vouliez joindre. De cette façon nous obtenons une réponse de chaque hôte sur notre chemin, et pouvons voir quel hôte ne répond pas.
Pour une liste complčte de tous les types ICMP, voir l'appendice Types ICMP. Pour plus d'information sur ICMP lisez les documents et rapports :
RFC 792 - Internet Control Message Protocol par J. Postel.
| Une erreur peut apparaître chez vous quand vous bloquez certains types ICMP, mais dans mon cas tout fonctionne parfaitement quand je bloque tous les types ICMP non autorisés. |
Chaîne INPUT
La chaîne INPUT, utilise la plupart du temps les autres chaînes pour faire le plus gros du travail. De cette façon nous n'avons pas trop de charge provenant d'iptables, et il fonctionnera mieux sur les machines lentes. Ceci est fait en vérifiant les détails spécifiques qui peuvent ętre identiques pour beaucoup de paquets différents, en ensuite en envoyant ces paquets dans les chaînes spécifiées par l'utilisateur. En faisant ça, nous réduisons notre table de rčgles qui ne contient que le nécessaire pour le transit des paquets, et donc le pare-feu aura moins de charge pour filtrer les paquets.
En premier nous vérifions les mauvais paquets. C'est réalisé en envoyant tous les paquets TCP vers la chaîne bad_packets. Cette chaîne contient des rčgles qui vérifient les paquets mal formés ou d'autres anomalies. Pour une explication complčte sur la chaîne bad_tcp_packets, regardez dans la section La chaîne bad_tcp_packets de ce chapitre.
Ŕ ce niveau nous recherchons le trafic généré par les réseaux de confiance. Ce qui inclut l'adaptateur réseau et tout le trafic prevenant de celui-ci, ainsi que le trafic entrant et sortant de la boucle locale (loopback), avec toutes les adresses IP assignées (toutes les adresses y compris notre adresse IP Internet). Ainsi, nous avons choisi de placer la rčgle qui autorise l'activité du LAN vers le pare-feu en premier, car notre réseau local génčre plus de trafic de la connexion Internet. Ceci permet d'avoir moins de charge systčme pour apparier chaque paquet avec chaque rčgle, et c'est toujours une bonne idée de regarder quel type de trafic traverse principalement le pare-feu. En faisant cela nous rendons les rčgles plus efficaces, avec moins de charge sur le pare-feu et moins de congestion sur notre réseau.
Avant de nous attaquer aux rčgles "réelles" dans lesquelles nous déciderons quoi autoriser depuis l'Internet, nous avons placé une rčgle pour réduire la charge systčme. C'est une rčgle d'état qui autorise tous les paquets d'un flux ESTABLISHED ou RELATED vers l'adresse IP Internet. Cette rčgle a une équivalence dans la chaîne autorisée, qui est redondante ŕ celle-ci. Cependant, la rčgle --state ESTABLISHED,RELATED dans la chaîne autorisée a été conservée pour plusieurs raisons, vous pouvez donc copier-coller cette fonction.
Aprčs ça, nous apparions tous les paquets TCP de la chaîne INPUT qui arrivent dans l'interface $INET_IFACE, et les envoyons vers tcp_packets, comme précédemment décrit. Nous faisons maintenant la męme chose pour les paquets UDP sur l'interface $INET_IFACE et les envoyons vers la chaîne udp_packets, ensuite tous les paquets ICMP sont envoyés vers la chaîne icmp_packets. Normalement, un pare-feu devrait ętre plus difficile ŕ attaquer par des paquets TCP, que par des paquets UDP et ICMP. C'est le cas normal, mais souvenez vous, ce peut ętre différent pour vous. La męme chose peut ętre observée ici, comme avec les rčgles réseau spécifiques. Lesquelles génčrent le plus de trafic ? Sur les réseaux générant un important volume de données, c'est une absolue nécessité de vérifier cela, car une machine de type Pentium III peut ętre saturée par une simple table de rčgles contenant 100 rčgles avec une carte réseau ethernet 100 Mbit fonctionnant ŕ sa pleine capacité, si la table de rčgles est mal écrite. Il est important de regarder ça de prčs.
Ici nous avons une rčgle supplémentaire, qui est par défaut désactivée, et qui peut ętre utilisée pour évitez une journalisation excessive dans le cas oů nous avons un réseau Microsoft ŕ l'extérieur de notre pare-feu Linux. Les clients Microsoft ont la mauvaise habitude d'envoyer des tonnes de packets multicast vers la plage 224.0.0.0/8, donc nous avons la possibilité de bloquer ces paquets ici. Il existe deux autres rčgles faisant ŕ peu prčs la męme chose sur la chaîne udp_packets décrite dans La chaîne UDP.
Avant de tester la stratégie par défaut de la chaîne INPUT, nous la journalisons pour savoir s'il existe des problčmes/bugs. Ce peut ętre soit un paquet que nous ne voulons pas autoriser, soit une chose qui peut se révéler néfaste pour nous, ou finalement un problčme dans notre pare-feu qui n'autorise pas le trafic qui devrait ętre autorisé. Nous ne journalisons pas plus de 3 paquets par minute car nous ne voulons pas surcharger nos journaux, ainsi nous plaçons un préfixe pour toutes les entrées de journalisation et savons donc d'oů ils proviennent.
Tout ce qui n'a pas été capturé sera DROPé par la stratégie par défaut de la chaîne INPUT. Voir la section Mise en place des actions par défaut dans ce chapitre.
Chaîne FORWARD
La chaîne FORWARD contient quelques rčgles dans notre scenario. Nous avons une seule rčgle qui envoie tous les paquets vers la chaîne bad_tcp_packets, laquelle est également utilisée dans la chaîne INPUT comme décrit précédemment. La chaîne bad_tcp_packets est construite de façon qu'elle puisse ętre utilisée dans plusieurs chaînes, sans regarder quel paquet la traverse.
Aprčs cette vérification des mauvais paquets TCP, nous avons les rčgles principales dans la chaîne FORWARD. La premičre rčgle autorise tout le trafic depuis notre $LAN_IFACE vers n'importe quelle autre interface librement, sans restrictions. En d'autres termes, cette rčgle autorise tout le trafic depuis le LAN vers l'Internet. La seconde rčgle autorise le trafic en retour ESTABLISHED et RELATED ŕ travers le pare-feu. Ce qui veut dire qu'elle autorise les connexions initiées par notre réseau local ŕ circuler librement dans le LAN. Ces rčgles sont nécessaires pour que notre réseau local puisse accéder ŕ l'Internet, car la stratégie par défaut de la chaîne FORWARD est placée ŕ DROP. C'est adroit, car elle autorise les hôtes de notre réseau local ŕ se connecter ŕ des hôtes sur Internet, mais en męme temps elle bloque les hôtes depuis Internet leur interdisant de se connecter aux hôtes de notre réseau interne.
Enfin, nous avons également une chaîne de journalisation pour tous les paquets qui ne sont pas autorisés dans un sens ou dans l'autre ŕ traverser la chaîne FORWARD. Ceci concerne principalement les paquets mal formés ou autre problčme. Une cause peut ętre une attaque de hacker, et une autre des paquets mal formés. C'est exactement la męme rčgle que celle utilisée dans la chaîne INPUT sauf pour le préfixe de journalisation, "IPT FORWARD packet died: ". Le préfixe de journalisation est principalement utilisé pour séparer les entrées de journaux, et peut ętre utilisé pour savoir d'oů les paquets ont été journalisés et connaître certaines options d'en-tęte.
Chaîne OUTPUT
Comme nous utilisons notre machine en partie comme pare-feu et en partie comme station de travail, nous autorisons tout ce qui sort de cette machine qui a une adresse source $LOCALHOST_IP, $LAN_IP ou $STATIC_IP. Enfin nous journalisons tout ce qui est DROPé. S'il y a des paquets DROPés, nous voulons savoir quelle action entreprendre contre ce problčme. Soit c'est une erreur, soit c'est un paquet mystérieux qui peut ętre usurpé. Enfin nous DROPons le paquet dans la stratégie par défaut.
Chaîne PREROUTING de la table nat
La chaîne PREROUTING fait ŕ peu prčs ce qu'elle indique, elle traduit les adresses réseau sur les paquets avant la décision de routage qui les envoie vers les chaînes INPUT ou FORWARD dans la table de filtrage. La seule raison que nous avons de parler de cette chaîne ici est que nous ne faisons aucun filtrage dans celle-ci. La chaîne PREROUTING est traversée seulement par le premier paquet d'un flux, ce qui veut dire que tous les autres paquets ne seront pas vérifiés dans cette chaîne. Dans ce script, nous n'utilisons pas du tout la chaîne PREROUTING, cependant, c'est le bon endroit si nous voulons faire du DNAT sur des paquets spécifiques, par exemple si nous voulons héberger notre serveur web dans notre réseau local. Pour plus d'information sur la chaîne PREROUTING, lire le chapitre Traversée des tables et des chaînes.
| La chaîne PREROUTING ne doit pas ętre utilisée pour quelque filtrage que ce soit, car parmi d'autres choses, elle n'est traversée que par le premier paquet d'un flux. Elle devrait ętre utilisée uniquement pour la traduction d'adresse réseau, ŕ moins que vous ne sachiez réellement ce que vous faites. |
Démarrage de SNAT et la chaîne POSTROUTING
Notre derničre mission est d'activer la traduction d'adresse réseau. En premier nous ajoutons une rčgle ŕ la table nat, dans la chaîne POSTROUTING qui NAT tous les paquets provenant de notre interface et allant vers Internet. Pour moi c'est eth0. Cependant, il existe des variables spécifiques ajoutées aux scripts d'exemples qui peuvent ętre utilisées automatiquement pour configurer cela. L'option -t indique ŕ iptables dans quelle table insérer la rčgle, dans notre cas c'est la table nat. La commande -A indique que nous voulons lier une nouvelle rčgle ŕ une chaîne existante nommée POSTROUTING et -o $INET_IFACE nous dit d'apparier tous les paquets sortants sur l'interface INET_IFACE (ou eth0, par défaut dans ce script) et enfin nous plaçons la cible pour faire du SNAT sur les paquets. Ainsi tous les paquets qui apparient cette rčgle seront SNATés pour vérifier qu'ils viennent de l'interface Internet. Notez que vous devez indiquer l'adresse IP ŕ donner aux paquets sortants avec l'option --to-source envoyée ŕ la cible SNAT.
Dans ce script nous avons choisi d'utiliser la cible SNAT au lieu de MASQUERADE pour deux raisons. La premičre est que ce script est supposé s'exécuter sur un pare-feu qui possčde une adresse IP statique. La raison suivante est qu'il est plus rapide et plus efficace d'utiliser la cible SNAT si possible. Bien sűr, nous l'utilisons aussi pour montrer comment elle fonctionne dans un exemple réel. Si nous n'avons pas d'adresse IP statique, nous utiliserons la cible MASQUERADE car elle offre des fonctions simples et faciles pour faire du NAT, mais elle récupčre automatiquement l'adresse IP qui sera utilisée. Ceci consomme un peu plus de temps systčme, mais c'est trčs avantageux si vous utilisez DHCP. Si vous voulez avoir une vue plus détaillée de la cible MASQUERADE, regardez le script rc.DHCP.firewall.txt.